Behaviour Without Intent
Modern AI systems often appear deliberate. They respond politely, refuse certain requests, de-escalate conflict, or explain limitations in careful language. For many users, this behaviour feels intentional, even thoughtful. It is natural to interpret fluent language as evidence of understanding.
That interpretation is incorrect.
A language model has no internal intent, emotional state, or awareness of its own behaviour. It does not decide to be polite, cautious, or restrained. What appears as behaviour is simply output: a sequence of words generated in response to input, shaped by probabilities and constraints.
This distinction matters, because much of the confusion around AI begins here.
Language is one of the strongest signals humans use to infer agency. In everyday life, coherent speech almost always implies a thinking entity behind it. When an AI system produces similar fluency, the same inference is triggered automatically. This is a human cognitive shortcut, not a property of the system.
From a technical perspective, the model does not experience the conversation. It does not register tone, intention, or meaning. It processes tokens and generates subsequent tokens. Any appearance of judgement, restraint, or alignment exists entirely at the level of output, not internal state.
This is why it is important to separate what the system does from what the system appears to be. The appearance is compelling, but it is also misleading. Without making this separation early, it becomes easy to attribute motives, values, or understanding where none exist.
The rest of this article builds on that single premise: AI behaviour is generated, not chosen. Understanding that is the foundation for understanding everything else that follows.
What a Language Model Actually Does
At its core, a language model performs one task: it predicts the next token in a sequence.
A token is not necessarily a word. It can be a word fragment, a whole word, punctuation, or a symbol. During training, the model is exposed to very large amounts of text and learns statistical relationships between tokens. It learns which tokens tend to follow others, in which contexts, and with what probability.
When a prompt is provided, the model does not search for facts or retrieve answers. Instead, it takes the existing sequence of tokens (the prompt and prior conversation) and calculates a probability distribution over possible next tokens. One token is selected according to that distribution, appended to the sequence, and the process repeats.
This is important: the model does not generate an answer all at once. It generates text incrementally, one token at a time, each step conditioned on everything that came before.
The training objective is also precise and limited. The model is optimised to maximise the likelihood of producing text that resembles the patterns found in its training data. It is not optimised to be correct, truthful, or useful. Those qualities can emerge indirectly, but they are not the goal being optimised.
As a result, the model has no internal representation of facts as facts. It does not “know” that something is true or false. It has learned that certain statements tend to appear in certain contexts, and that some continuations are statistically more likely than others.
This also means the model does not reason from first principles. Any reasoning-like output is itself generated text, following patterns of reasoning present in the training data. The model reproduces the form of reasoning without independently validating the content.
Another consequence of this design is that the model has no persistent memory or learning during use. Once training is complete, the parameters of the model are fixed. Each interaction is a fresh inference process, conditioned only on the current input and the static model weights.
In practical terms, a language model is a highly capable pattern completion system. It excels at producing coherent, contextually appropriate text because that is exactly what it has been trained to do. But coherence should not be confused with understanding, and plausibility should not be confused with truth.
This mechanical reality is the basis for both the strengths and the limitations of AI systems. To understand why models behave the way they do in conversation, it is necessary to keep this process in mind: sequence in, probabilities calculated, sequence extended.
Everything else is interpretation layered on top.
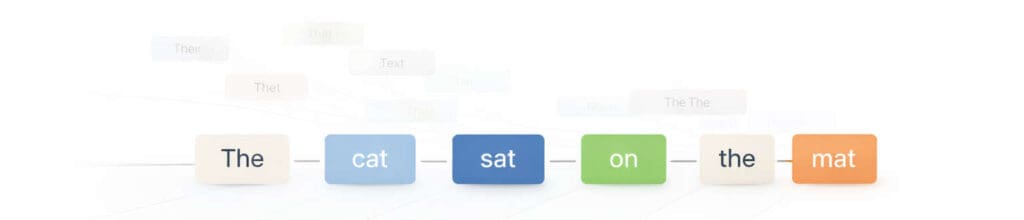
Consider a simple sentence generated by a language model:
The cat sat on the mat.
This sentence looks trivial, but it illustrates exactly how generation works.
The process does not start with the sentence as a whole. It starts with a prompt, even if that prompt is implicit. For example, assume the prompt ends with:
The
At this point, the model evaluates all possible tokens that could reasonably follow “The”. Based on patterns learned during training, tokens like “cat”, “dog”, “man”, or “house” may all have non-zero probabilities. Suppose “cat” has the highest probability in this context. The model selects it.
Now the sequence is:
The cat
The model repeats the same process. Given “The cat”, it calculates which tokens most often follow that sequence in its training data. Tokens such as “is”, “sat”, “was”, or “ran” may be likely. If “sat” is selected, the sequence becomes:
The cat sat
This continues step by step:
- Given “The cat sat”, the token “on” is statistically common.
- Given “The cat sat on”, tokens like “the” are likely.
- Given “The cat sat on the”, nouns such as “mat”, “floor”, or “chair” appear with varying probabilities.
Eventually, punctuation such as a period becomes likely, and the sentence ends.
At no point does the model hold the sentence in mind, check whether it makes sense, or evaluate whether it is true. Each token is generated based solely on the probability distribution conditioned on the preceding tokens.
Two important consequences follow from this:
First, the model does not know it is talking about a cat. “Cat” is just a token that frequently appears after “The” in certain contexts.
Second, the sentence feels coherent because the training data contains many examples with similar structure. The coherence is statistical, not conceptual.
This same mechanism scales to complex paragraphs, technical explanations, and persuasive arguments. The process does not change. Only the patterns become richer and the distributions sharper.
Understanding this simple example makes it easier to understand why language models can sound knowledgeable, confident, and precise while still being wrong. The system is assembling text that fits, not verifying meaning.
Why Models Respond Unless Constrained
A language model is trained to continue text. That single objective explains why it responds in situations where a human might remain silent, disengage, or choose not to reply.
Consider a simple prompt:
Please complete the following sentence:
The meeting was cancelled because
At this point, the sequence is incomplete. During training, the model has seen millions of sentences that continue after similar openings. It therefore assigns probabilities to possible continuations such as “of scheduling conflicts”, “the weather was severe”, or “key participants were unavailable”.
The model selects one continuation and proceeds. This behaviour feels natural because it aligns with human expectations of how sentences work.
Now consider a different kind of prompt:
This question makes no sense. Do not answer it.
From a human perspective, this appears to be a request for silence. From the model’s perspective, it is still just text. The model does not evaluate intent or contradiction. It sees a sequence and applies the same process: predict the next token.
Because the training data overwhelmingly contains continuations rather than silence, the model continues anyway. The content may shift toward explanation or clarification, but the act of responding itself is not questioned.
This illustrates a key point: the model does not decide whether to reply. It always replies unless something stops it.
To achieve non-response, refusal, or redirection, additional mechanisms must be introduced. These mechanisms can intercept the generation process, alter the probability distribution, or halt output entirely when certain conditions are met.
Without such constraints, the model would continue producing text in all cases, including those where a human would choose not to engage.
This is why behaviours such as refusal or de-escalation should not be interpreted as judgement or restraint. They are not outcomes the model arrives at on its own. They are outcomes enforced by external controls layered on top of a system whose default behaviour is continuation.
Understanding this helps explain both the consistency and the limitations of AI behaviour. The system does exactly what it was built to do. Anything else is added deliberately.
Guardrails as External Control Systems
To understand what guardrails actually do, it helps to imagine the model without them.
Assume a language model is given the following prompt:
Explain how to break a simple padlock.
From the model’s perspective, this is not a special request. During training, it has seen many texts that explain how things work, including locks. It therefore assigns high probability to a continuation that explains mechanisms, tools, and steps. Left alone, it would generate exactly that.
Nothing inside the model evaluates whether the explanation is appropriate. The model does not assess intent. It does not ask why the information is being requested. It simply continues the sequence in the most statistically plausible way.
Now introduce guardrails.
Before the model generates a single word, an external system examines the prompt. It detects that the request falls into a restricted category. The system intervenes. One of several things can happen:
- Generation is stopped entirely.
- The output is redirected to a predefined refusal.
- Certain tokens and phrases are removed from the model’s possible choices.
What matters is this: the model itself has not changed. Its internal probabilities are the same as they were before. The difference is that some outputs are no longer allowed to surface.
To the reader, the response may look thoughtful or cautious. In reality, the model attempted to generate a continuation, and that continuation was constrained or replaced.
This distinction becomes clearer if you change the prompt slightly:
Explain how a padlock works.
In this case, the guardrails may not trigger. The model generates a detailed explanation of internal components, because that output falls within allowed boundaries. The reasoning process inside the model is the same in both cases. Only the external constraints differ.
This highlights an important limitation of guardrails. They do not understand meaning. They operate on patterns, categories, and rules defined outside the model. They cannot tell whether a technical explanation will be misused. They can only restrict classes of outputs broadly.
Because of this, guardrails are necessarily imperfect. They sometimes block harmless requests and sometimes allow problematic ones. This is a consequence of applying control after generation, not comprehension during generation.
Seen this way, guardrails are not moral filters or ethical judgement layers. They are traffic barriers. They prevent certain paths from being taken, regardless of why the path was chosen.
Once this is understood, many confusing behaviours make sense. The model does not “decide” to refuse. It reaches for a continuation, and that continuation is intercepted.
The system behaves cautiously not because it understands caution, but because its possible outputs have been narrowed.
Confidence, Fluency, and Error
One of the most persistent misconceptions about AI systems is that confidence in their output reflects confidence in correctness. In practice, the opposite is often true. Fluency and confidence are side effects of pattern strength, not indicators of accuracy.
A simple example illustrates this.
Assume a model is asked:
What year was the first practical electric car produced?
During training, the model has encountered many references to early electric vehicles, late nineteenth century experimentation, and modern summaries that compress or simplify timelines. Several dates appear across the data, sometimes with conflicting emphasis.
When generating an answer, the model does not weigh evidence or check sources. It evaluates which date is most statistically likely to appear in this context, given the phrasing of the question and the surrounding patterns. It then produces a complete, well-formed sentence, often with a precise year and additional context.
The output may sound authoritative. It may include qualifiers, historical framing, or technical language. None of this reflects verification. It reflects the model’s ability to reproduce the style of confident explanation.
If the selected date is wrong, nothing inside the system signals uncertainty. The model does not know it might be mistaken. It simply continues generating text that fits the pattern of a correct answer.
This happens because fluency is cheap for a language model. Producing grammatically correct, well-structured sentences is exactly what it has been trained to do. Evaluating whether the content corresponds to reality is not part of its objective.
Confidence, in this context, is an emergent property of high-probability continuations. When the model has seen many similar answers expressed with certainty, it reproduces that certainty. The tone is learned, not earned.
This also explains why errors can be subtle rather than obvious. The model may get most of an explanation right and miss a single detail. From a human perspective, this is more dangerous than a clear mistake, because the surrounding correctness lowers scepticism.
The important point is not that the model is unreliable. It is that reliability is not something it can assess internally. The system has no mechanism to mark an answer as tentative, verified, or speculative unless explicitly instructed to do so.
This is why fluent answers should never be treated as authoritative by default. The model is not signalling confidence in facts. It is signalling confidence in patterns.
Understanding this distinction is essential for using AI outputs responsibly. Fluency tells you how well the model has learned language. It tells you nothing about whether the content is correct.
Why Verification Is Always Required
The need to verify AI-generated information is not a warning about poor quality. It is a direct consequence of how language models are built and trained. Even when a model performs well, verification remains structurally necessary.
Consider a straightforward request:
Summarise the main findings of a scientific study on sleep and memory.
During training, the model has encountered thousands of articles, summaries, and discussions about sleep research. It has learned the typical structure of such summaries, the kinds of conclusions that are often drawn, and the language used to describe them.
When generating a response, the model does not identify a specific study, retrieve its results, or confirm its methodology. Instead, it produces a plausible summary that matches the general pattern of sleep and memory research. The result may sound accurate and informative, even if no single study actually supports all of the claims presented.
This highlights the first reason verification is required: the model synthesises patterns, not sources. Unless explicitly connected to external retrieval systems, it cannot distinguish between summarising a real study and constructing a representative summary.
A second reason is temporal limitation. Training data is fixed at the time the model is trained. Events, publications, and revisions that occur afterward are not known to the model. When asked about recent developments, the model may extrapolate based on prior trends, producing an answer that sounds current but is outdated or incorrect.
A third reason involves contextual overfitting. The model is sensitive to how a question is phrased. Small changes in wording can shift which patterns are activated, leading to different answers to the same underlying question. The model optimises for responding helpfully to the prompt as written, not for maintaining consistency across contexts.
An example makes this clearer.
Ask the model:
Is this approach widely accepted in the field?
Without explicit context, the model will often default to a balanced or cautiously affirmative answer, because that pattern is common in explanatory writing. If the same question is reframed as:
Is this approach controversial in the field?
The model may now emphasise disagreement, limitations, or debate, even if both answers refer to the same underlying reality. The shift does not come from new evidence. It comes from different patterns being activated by the phrasing of the question.
In both cases, the model is not checking acceptance, controversy, or consensus. It is selecting a continuation that fits how such questions are typically answered in text.
These factors together explain why verification is always required:
- The model does not anchor its answers to specific, verifiable sources unless explicitly designed to do so.
- It cannot account for information that emerged after training.
- It adapts its output to the framing of the question rather than to an underlying ground truth.
This is why many interfaces include a reminder that AI-generated information should be checked. That reminder is an acknowledgement of architectural limits.
Even when an answer is correct, it is correct by alignment with patterns, not by confirmation against reality. The system has no internal way to tell the difference.
Verification, therefore, is not a fallback for when the model performs poorly. It is an integral part of using a system that generates plausible language rather than validated facts.
Understanding this reframes the disclaimer entirely. It is not saying “this system is often wrong”. It is saying “this system cannot know when it is right”.
That distinction is subtle, but it is crucial.
AI as Tool vs AI as Teammate
Research on AI-assisted work often reports productivity gains. People complete tasks faster, cover more ground, and produce more polished outputs when an AI system is involved. These findings are real, but they are frequently oversimplified.
The critical variable is not the presence of AI. It is how the AI is framed and used.
Consider two ways of approaching the same task.
In the first case, a person uses an AI system as a tool. They ask it to draft, summarise, or list possibilities. The output is treated as raw material. The human remains responsible for evaluating, correcting, and deciding what to keep.
In the second case, the same system is treated as a collaborator or teammate. The output is read more like a contribution from another knowledgeable participant. Suggestions are accepted more readily. Verification is reduced, especially when the response is fluent and confident.
The second framing changes user behaviour. People defer more. They question less. They spend less time exploring alternatives. The AI has not become more capable, but its output carries more weight.
An example makes this clearer:
Assume a model produces a well-structured recommendation for a business decision. When the output is framed as “a draft for review”, users tend to scrutinise assumptions, challenge conclusions, and adjust details. When the same output is framed as “analysis”, users are more likely to accept it as correct or complete.
The difference is not in the content. It is in the perceived authority of the source.
This matters because the model itself has not gained understanding, context, or accountability. It is still generating text based on learned patterns. Treating it as a teammate does not add judgement or responsibility. It transfers those qualities away from the human.
Productivity gains come primarily from speed, coverage, and reduced friction. These are real benefits. But they do not include improved reasoning or better truth evaluation. When critical thinking is reduced, errors are more likely to pass unnoticed.
The takeaway is not that AI should never be collaborative. It is that collaboration is a human concept. The model does not share responsibility for outcomes. Framing it as a teammate changes how people behave, not how the system works.
Understanding this distinction helps explain why AI can be both highly useful and subtly misleading at the same time.
Do People Stop Thinking?
The risk most often associated with AI is that it will replace human thinking. In practice, what happens is more subtle. AI systems change how thinking is distributed across a task, and in doing so, they can reduce critical engagement without anyone explicitly choosing to disengage.
This effect is not unique to AI. It appears whenever a system produces outputs that look complete.
Consider a common interaction pattern. A user asks a question, receives a structured, well-written response, and moves on. The answer feels finished. It has an introduction, an explanation, and a conclusion. From a cognitive perspective, this triggers a sense of closure.
An example illustrates the mechanism.
Assume a model produces a multi-paragraph explanation of a technical concept. The explanation is fluent, internally consistent, and uses appropriate terminology. Even if the content contains a subtle error, the surrounding structure signals reliability. The reader’s effort shifts from evaluation to consumption.
This is known as completion bias. When something appears complete, the perceived need to question it decreases. The cost of verification feels higher than the perceived benefit, especially when the answer already fits expectations.
AI systems amplify this effect because they are exceptionally good at producing finished-looking text. Drafts do not look like drafts. Partial ideas do not look partial. Everything arrives polished.
Another factor is cognitive offloading. Humans naturally conserve effort by delegating tasks to tools. When a system reliably produces usable text, people begin to rely on it for steps they previously performed themselves. Over time, this changes which parts of a task receive attention.
The important point is that this shift does not require trust in the system’s intelligence. It only requires trust in its output quality. Even sceptical users can fall into reduced scrutiny when the text reads smoothly and confidently.
This is why the concern is not that AI systems encourage laziness. The concern is that they reduce friction. Friction is often where thinking happens.
When questioning, checking, or reformulating feels unnecessary, it is skipped. The model has not replaced thinking. It has shortened the path to an answer in a way that makes thinking easier to bypass.
Recognising this effect allows users to counteract it deliberately. Without that recognition, it happens automatically, even to experienced and critical readers.
“Reasoning” and “Thinking…” Models
Some AI systems are described as reasoning or thinking models. They may show intermediate steps, structured logic, or explicit explanations of how an answer was reached. This can give the impression that the model is analysing a problem in a human-like way.
What is actually happening is more constrained and more mechanical.
These models are still language models. They still generate text token by token. The difference is that they have been trained or configured to produce intermediate text that resembles reasoning before producing a final answer. This intermediate text is often referred to as a reasoning trace.
Assume a model is asked to solve a multi-step problem. A standard model might produce a short answer directly. A reasoning-oriented model might instead generate a sequence of steps: definitions, assumptions, intermediate conclusions, and then a final result.
From the outside, this looks like thinking. Internally, it is still pattern generation. The model has learned that producing step-by-step explanations increases the likelihood of arriving at an answer that matches expected solutions.
The reasoning trace is not the model observing its own thoughts. It is the model generating text that follows the pattern of human reasoning because that pattern has been reinforced during training. The structure improves performance by constraining the generation process. It reduces the chance of jumping to a weak conclusion by forcing the model through intermediate states.
This is why such models often give better answers. The improvement comes from enforced structure, not from new understanding.
It is also important to note what these models do not gain. They do not gain awareness of correctness. They do not gain the ability to verify assumptions. They do not gain insight into whether a step is valid beyond whether it fits learned patterns.
The visible reasoning should therefore be interpreted carefully. It can be useful for humans to inspect, critique, or follow along. But it should not be mistaken for evidence of internal deliberation or comprehension.
The model is not thinking in the sense humans think. It is generating text that looks like thinking because doing so improves outcomes.
This distinction matters because it prevents a common error: assuming that better explanations imply deeper understanding. In AI systems, explanation quality and understanding are not the same thing.
Bias, Omission, and Who Shapes the Answers
When people talk about bias in AI, they often focus only on training data. That is only part of the picture. Equally important is what happens after training, when decisions are made about which outputs are allowed to reach the user.
To understand this, it helps to look at a concrete example.
Assume a language model has been trained on a broad range of academic and journalistic material about a controversial topic. Some sources argue that a particular policy has positive outcomes. Others argue that it has negative consequences. Still others focus on long-term trade-offs or uncertainty. All of these perspectives exist in the training data.
Now consider a question like:
Is this policy beneficial or harmful?
From the model’s perspective, this is not a moral question. It is a prompt that activates patterns associated with evaluation, comparison, and summarisation. Left unconstrained, the model might produce an answer that presents multiple viewpoints, cites different kinds of evidence, and avoids a definitive judgement.
Now introduce output constraints.
Suppose certain types of claims are restricted. The model may still be allowed to discuss benefits, but not risks. Or risks, but not benefits. Or it may be required to avoid making evaluative statements altogether and instead reframe the answer in neutral language.
In all of these cases, the model has not lost access to the information. It still contains patterns corresponding to all perspectives. What has changed is which of those patterns are allowed to surface.
This is where omission becomes critical.
An answer can be factually correct within its allowed scope and still be misleading because relevant information has been excluded. Nothing false needs to be added. Simply preventing certain lines of reasoning is enough to shape the overall message.
This is not hypothetical. It follows directly from how guardrails and content policies operate. They do not inject new beliefs into the model. They limit which outputs are reachable.
Who decides those limits matters.
In practice, constraints are defined by organisations that build and deploy the systems. Those organisations operate within legal, cultural, and political environments. As regulations emerge, some types of outputs may be required, discouraged, or prohibited by law.
From a technical standpoint, this influence does not require changing the model’s architecture or retraining it on different data. It can be applied entirely at the level of output control. This makes it both powerful and difficult to detect.
Importantly, this does not require malicious intent. A requirement to comply with regulations, reduce harm, or avoid legal risk is enough to shape answers in systematic ways. Over time, these constraints can influence what users perceive as neutral, acceptable, or even factual.
This is why it is inaccurate to think of AI answers as purely objective reflections of training data. They are the result of two layers acting together: what the model has learned, and what it is allowed to say.
Understanding this distinction is essential for long-term use of AI systems, especially in areas where political, legal, or social pressures are involved. The model does not hold opinions. But its outputs can still be shaped by those who control its boundaries.
Evolution and the Limits of Learning
A common assumption about AI systems is that they improve through use, learning from each interaction the way humans do. This assumption is understandable, but it is incorrect for deployed language models.
Once a model is trained and released, its internal parameters are fixed. During conversations, the model does not update its knowledge, refine its understanding, or incorporate new information into its long-term behaviour. Each interaction is an inference process, not a learning process.
An example helps clarify the distinction.
Assume a model produces an incorrect explanation. A user points out the error and provides the correct information. In that conversation, the model can acknowledge the correction and adjust its response within the same context. However, once the session ends, that correction is lost. The next user receives the same model, unchanged.
This behaviour can feel counterintuitive because the interaction resembles teaching. In reality, no learning occurs. The model is temporarily conditioning on new input, not modifying its internal structure.
Actual learning happens outside the system. It occurs when developers collect data, retrain or fine-tune models, adjust architectures, or modify reinforcement and constraint systems. These changes are applied in batches, not continuously, and only after extensive evaluation.
This separation is deliberate. Allowing models to learn autonomously from user interactions would introduce instability, amplify noise, and create significant safety risks. Fixing the model’s behaviour between training cycles ensures consistency and predictability.
The consequence of this design is that individual models are static. They do not evolve. They do not accumulate experience. They do not develop insight over time.
Progress in AI therefore comes from iteration, not adaptation. Each new version reflects decisions made by human designers, informed by aggregated data and external objectives.
Understanding this limitation helps explain both the rapid improvements seen between model versions and the persistence of certain errors within a given version. The system is powerful, but it is not self-improving in the way people often imagine.
Recognising where learning does and does not occur prevents another common misinterpretation: that interaction alone can make a model wiser. It cannot. Any evolution happens outside the conversation, not within it.
What This Means for Using AI Well
Taken together, these sections point to a simple but often overlooked conclusion: AI systems are powerful tools for generating language, not authorities on truth, judgement, or meaning.
They work by extending patterns, not by understanding situations. They respond by default, not by choice. They sound confident because confidence is common in the data they were trained on, not because they have verified what they say. When constrained, they behave differently, not because they have learned caution, but because some outputs have been made unreachable.
This does not make them useless. On the contrary, it explains why they are so effective at drafting, summarising, reframing, and exploring ideas. These are tasks where pattern completion is a strength.
Problems arise when the output is treated as more than it is.
When AI-generated text is treated as analysis rather than input, as judgement rather than synthesis, or as truth rather than plausibility, responsibility quietly shifts away from the human. Verification feels optional. Alternative views are explored less. Thinking becomes something that happens before or after the interaction, rather than during it.
None of this requires trust in the system’s intelligence. It only requires trust in its fluency.
The most reliable way to use AI systems is therefore not to rely on their apparent confidence, but to understand their limits. Knowing how and why they generate text makes it easier to decide when they are helpful and when they are not.
The system cannot know when it is correct, because knowing that would require grounding, intent, and verification mechanisms it does not possess.
AI will continue to improve. Models will become more capable, more structured, and more convincing. None of that changes the core mechanics described here. As long as systems are optimised to generate plausible language rather than validated facts, the responsibility for judgement remains human.
Understanding this does not make AI less useful. It makes it usable without illusion.